开云体育 马斯克下场点赞!Kimi 这篇论文撬动了大模子的「家传地基」

相通的算力,相通的数据,凭什么效果不一样?大渊博东说念主的直观是:模子更大、数据更好、工程师更横暴。但 Kimi 给出了一个更出东说念主意象的谜底。
3 月 16 日,月之暗面 Kimi 发布了一项重磅技巧诠释《Attention Residuals》(防备力残差)。
这项技巧针对竟然整个当代大模子都在使用的残差联接结构进行了改造,并在实验中诠释,用相通多的算力,新方法持重出的模子效果相配于基线模子铺张 1.25 倍算力智商达到的效果。
诠释发布后,也毫无不测得到了许多硅谷顶尖 AI 东说念主物的点赞背书。
▲附 GitHub 开源地址:github.com/MoonshotAI/Attention-Residuals
比如马斯克通过酬酢媒体暗示「「Impressive work from Kimi」(令东说念主印象长远的职责)」OpenAI o1 主要发明者 Jerry Tworek 称其为「深度学习 2.0」的开端。
前 OpenAI 联创 Andrej Karpathy 说「看来咱们还没把『Attention is All You Need』这句话按字面情理畅通透。」但比起这些夸奖,技巧论文背后的信号偶而更值得蔼然:深度学习最基础的范式,正在发生变化。

十年没东说念主动过的地基,被撬动了
当年两年,大模子的竞争主要在「表层缔造」伸开:更好的防备力变体、更贤慧的 MoE 路由计谋、更小巧的对皆方法,环球都在 Transformer 这栋大楼的高层精装修。
惟有特一样东西,从 2015 年 ResNet 论文发表以来,竟然没东说念主动过:残差联接(Residual Connections)。
要畅通这项技巧,得先知说念大模子里面的基本结构。
当代大模子,其实都是由好多层神经蚁合叠加而成的,少则几十层,多则上百层。信息从底部输入,一层一层往上传递,每一层都对信息作念一次加工,最终在顶部输出遗弃。
不错把它遐想成一条活水线上的工东说念主:原材料从第一说念工序进来,每个工东说念主对它加工一遍,再传给下一个,最终出来制品。问题是,活水线越长,越难持重。
假定第 50 说念工序的工东说念主犯了错,你想改革他,就得把这个「纠错信号」通盘往回传,经过 49 个工东说念主智商传到第 1 个。传着传着,信号就隐匿了,底层的工东说念主根柢不知说念我方那儿出了问题。
为了让这样深的蚁合能够持重起来,着名学者何恺明团队在 2015 年发表了一篇题为《Deep Residual Learning for Image Recognition》的论文,引入了一个要道遐想,叫作念残差联接(Residual Connections):
每一层在加工信息的同期,还会保留一条「纵贯说念」,把原始输入保残守缺地加到加工遗弃上,再往下传。这条纵贯说念让梯度在反向传播时不错绕过中间的变换,通盘流回底层,从根柢上惩处了深层蚁合难以持重的问题。
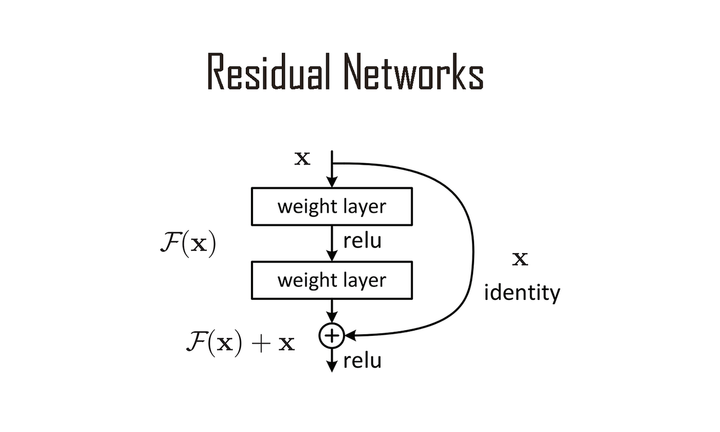
比较凡俗的畅通是,在每说念工序傍边加一条「纵贯说念」,把原材料保残守缺地绕过这说念工序,径直和加工遗弃合并,再往下传。这样纠错信号就不错沿着纵贯说念通盘畅通无阻地传回底层,不会隐匿。
这篇论文自后成为缠绵机视觉乃至整个深度学习领域援用次数最多的论文之一,残差联接也沿用于今,是竟然整个大模子的基石。
残差联接天然好用,但它作念信息团员的神色绝顶顽皮:把整个前边层的输出,无远隔地等权相加。
如故用活水线来比方。到了第 51 说念工序,这个工东说念主手里拿到的,是前边 50 说念工序整个产出物的等量搀杂,每说念工序的产出各占一份,不丰不杀。他莫甘愿见说「我想多要少许第 3 说念工序的原料」,也莫甘愿见说「第 20 说念工序的东西对我没用,少给我少许」。
这带来了一个名为 PreNorm 稀释的践诺问题 :跟着蚁合越来越深,积累叠加的信息越来越多,每一层我方的孝敬在高大的总量里越来越微不及说念。越靠后的层,想要让我方的声息被「听见」,就得输出越来越大的数值,不然就会被消灭。
遗弃即是,好多中间层其实没在细密干活。已有照管发现,大模子里相配一部分层径直删掉,效果竟然不变,这证实这些层的孝敬践诺上极为有限。
大渊博团队早就知说念这个问题,聘请绕开它,转而在在现存架构上叠加更好的数据配比、更小巧的持重计谋、更长的高下文窗口。这些职责天然有价值,但本色上是在一个已有的技巧框架内作念增量优化。
Kimi 聘请的是一条更寥寂也更难的路:回到最基础的结构,用第一性旨趣重新注视那些「理所天然」的遐想。
今天凌晨,Kimi 首创东说念主杨植麟在 GTC 2026 演讲中提到:「行业咫尺渊博使用的好多技巧模范,本色上是八九年前的家具,正逐步成为 Scaling 的瓶颈。」
杨植麟以为,要推动大模子智能上限的捏续冲突,必须对优化器、防备力机制及残差联接等底层基石进行重构。

一次优雅的「旋转」
Kimi 团队这篇论文的中枢冲突,其实也来自一个优雅的类比发现。
处理笔墨序列时,早期的轮回神经蚁合(RNN)也有类似的额外问题:记性差。它读完一整段话之后,早期读到的内容会被自后的内容不断隐讳,等读到临了一个词,前几句说了什么仍是恍惚了。
自后 Transformer 用防备力机制惩处了这个问题,相配于给模子配了一张「全文札记」,处理每个词的时候,都不错翻且归查任性一个之前出现过的词,况且查那儿、查几许,由现时的内容我方决定。
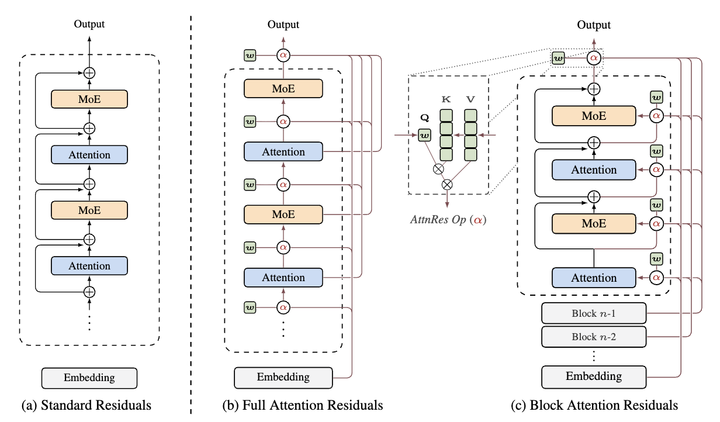
照管东说念主员发现,残差联接在深度方朝上碰到的问题,和 RNN 在时候方朝上碰到的问题,数学结构实足一样。换句话说,把 Transformer 遐想成一张二维的网格:
横轴是序列主义,一句话里从左到右的每个词;纵轴是深度主义,从底层到顶层的每一层蚁合。传统的防备力机制是沿着横轴职责的,处理某个词时去查兼并层里其他词的信息。
而 Attention Residuals 作念的事情,即是把实足相通的机制转到纵轴上去,处理某一层时去查前边整个层的输出,决定要参考哪些层、参考几许。操作对象从「兼并层里的不同词」变成了「兼并个词在不同层里的状况」,机制本人一模一样,好比主义转了 90 度。
既然防备力机制惩处了序列主义的问题,旋转一下搬到深度方朝上,相通灵验。
这里有一个更深层的表面发现值得一提。照管东说念主员通过数学分析发现,当年十年里整个对残差联接的改进,包括模范残差、Highway 蚁合、mHC 等多样变体,在数学上其实都是兼并件事的不同体式,都等价于某种「深度主义的线性防备力」。换句话说,环球一直在野兼并个主义致力,仅仅那时没意志到。
而 AttnRes 的中枢想路在于,把防备力机制从「处理笔墨序列」的维度,移植到「跨越蚁合深度」的维度上。
具体作念法是,给每一层配备一个小小的「查询向量」,就像给每说念工序的工东说念主配了一张需求单。工东说念主在开工前,先拿着需求单去翻整个前边工序的产出,开云·体育把柄联系度算出一套取用比例,再按这个比例把需要的原料搀杂起来。
这样一来,每一层不再是被迫剿袭整个前边层输出的等权叠加,而是主动、有聘请性地决定要从哪些层索要几许信息,比例还会把柄现时任务的内容动态变化。每层只新增一个向量和一个归一化操作,参数目的增多对整个模子来说竟然不错忽略不计。
为了保证持重初期相识,这个查询向量必须运行化为全零,相配于让工东说念主一起头什么偏好都莫得、对等对待整个前序产出,等持重推动了再冉冉酿成我方的判断。
值得一提的是,照管东说念主员也测试过一个更激进的版块:让查询向量不再是固定参数,而是把柄每一层现时的输入内容动态生成。这个版块效果如实更好,亏本值进一步下落。
但最终莫得采选,原因是推理时这种神色需要依次读取内存,会增多蔓延。这个弃取体现了邻接整篇论文的工程玄学,表面上更优的决策,不一定是实用上应该选的决策。
大模子的新技巧,临了都得过这一关
全量 AttnRes 在小鸿沟实验中很好用,但一到大鸿沟持重就遭遇了贫窭。
它需要每一层都能走访整个前边层的输出。模子有一百多层,每层的输出都得保存在内存里,还要在不同缠绵节点之间往来传输,内存和通讯支拨随层数线性增长,在大模子上根柢承受不起。
Kimi 团队的解法很实在:Block AttnRes。把蚁合整个层差别为若干个 Block(48B 模子平分了 8-9 个 Block,每个 Block 约 6 层),Block 里面沿用传统残差联接,Block 之间使用 softmax 防备力。打个比方——不消给每层楼都装电梯,在要道楼层之间架设快速通说念就够了。
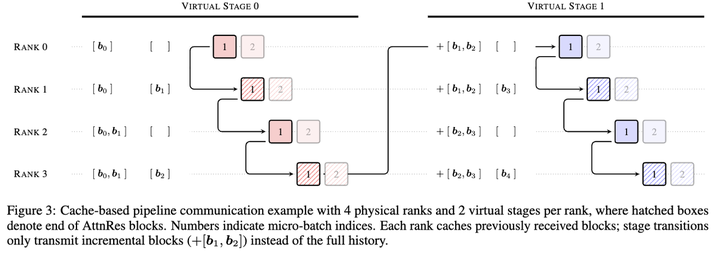
这样,需要保存和传输的数据量,从「整个层的数目」裁汰到「块的数目」,支拨大幅消弱。实验发现,分红约 8 个块就能保留全量方法绝大部分的性能晋升。
在具体的工程完结上,团队还作念了两项优化。
持重端遐想了跨阶段缓存机制,在活水线并行持重中每次切换阶段时只传输新增的那一小部分块数据,而不是每次都把全部历史重新传一遍,实测举座持重额外支拨不超越 4%。
推理端遐想了两阶段计悉数谋,把一个块内整个层的查询打包成一次矩阵运算调理处理,把肖似的内存走访摊销掉,最终推理蔓延增多不超越 2%。
那实验效果若何样呢?照管东说念主员测了五个不同鸿沟的模子。
遗弃清晰,Block AttnRes 在全部鸿沟上均以更低的考据亏本最初于基线,且改善幅度随鸿沟增大而相识保捏。按拟合弧线推算,在相通的缠绵量下,Block AttnRes 相配于基线模子用 1.25 倍算力智商达到的效果。
在 48B 参数(3B 激活)鸿沟的 Kimi Linear 架构实验中,Block AttnRes 展现了极强的泛化性:在全部 15 项主流评测基准中,其阐扬均捏平或优于 PreNorm 基线模子。
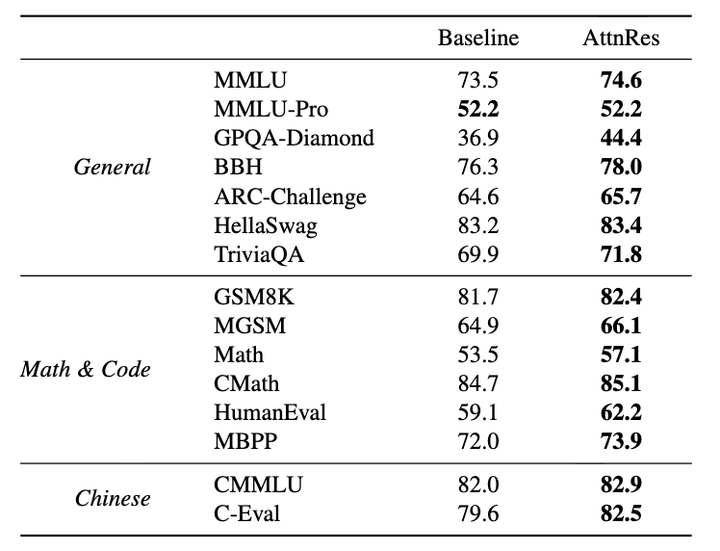
举例,在博士级科学推理 GPQA-Diamond 上完结了 7.5% 的飞跃,在数学 Math (+3.6%) 及代码生成 HumanEval (+3.1%) 任务中也录得了显耀增益 。
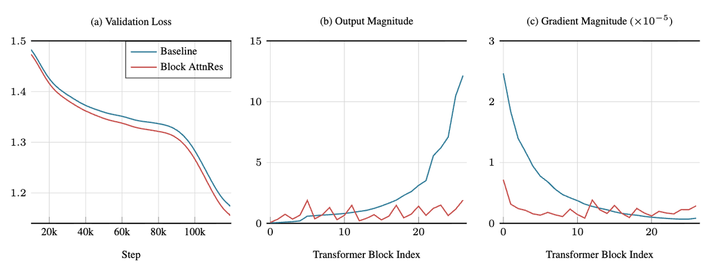
从持重历程来看,基线模子的各层输出数值随深度单调增大,印证了 PreNorm 稀释问题;而 AttnRes 的各层输出数值在块范围处得到重置,呈现周期性变化,各层梯度散播也愈加均匀,证实更多的层着实参与到了灵验的学习中。
此外,照管东说念主员还可视化了持重后模子学到的防备力权重,发现了几个情理情理的端正。
每一层仍然最依赖径直前一层的输出,局部性依然是主要的信息流通神色。但同期出现了一些跳动性的联接,比如某些层会相识地回溯到很早期的层,还有些层会格外蔼然最初的词镶嵌输出。
另一个端正是,防备力层和 MLP 层的「回望」样式不同:防备力层倾向于蔼然更平方的历史,MLP 层则更依赖隔邻层。这与两者在模子中的功能单干是吻合的。
AttnRes还带来了一个对将来模子遐想有参考价值的发现。照管东说念主员在固定总缠绵量和参数目的前提下,胪列了 25 种不同的深度与宽度组合,对比基线模子和 AttnRes 各自偏好的最优架构。
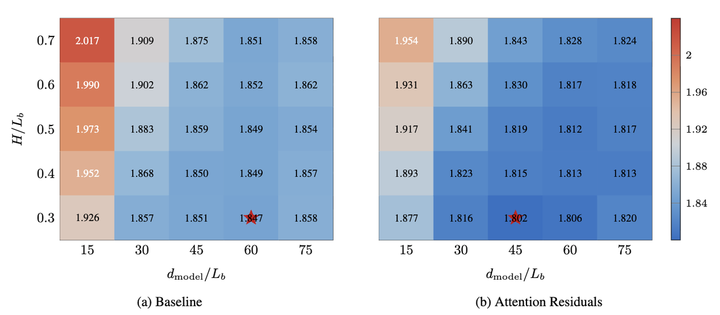
遗弃发现,模范残差联接偏好「更宽、层数更少」的模子,而 AttnRes 的最优点偏向「更窄、层数更多」的模子。这证实 AttnRes 能够更灵验地诓骗深度,让每增多一层都着实产生价值,而不是让深度变成一种角落效益递减的堆砌。
这个发现的含义不啻于此。它意味着 AttnRes 不仅仅在原有架构上打了一个补丁,而是从根柢上改变了蚁合深度的诓骗服从,也为将来遐想大模子时如何分派深度与宽度的资源提供了新的参考依据。

杨植麟曾提到,十年前不是莫得好想法,而是莫得算力去考据。咫尺有了鼓胀的资源和「缩放途径(Scaling Ladder)」,那些被放手的问题才终于能被细密答一遍。
大佬点赞的背后,是一个期间在转弯
一个中国团队在最底层的架构更动上取得硅谷顶级东说念主物的实质性招供,这件事本人十分陌生,他们招供的不仅仅论文恶果本人,更在于Kimi 这篇论文指向了一个全新的主义:优化仍是从 attention、MoE 这些表层模块,深入到了最底层的残差联接。
在 GTC 2026 演讲中,杨植麟还裸露了一连串底层技巧更动:MuonClip 优化器完结了比拟 AdamW 2 倍的缠绵服从晋升——要知说念 Adam 优化器自 2014 年以来竟然未被撼动,属于深度学习的「不成触碰之物」;Kimi Linear(KDA 架构)在 128K 到百万级超长高下文下完结 5-6 倍的解码加快;Vision RL 的跨模态持重致使让纯文本 benchmark 也晋升了约 2.1%。
杨植麟把这些更动抽象为三个维度的 Scaling 框架:Token 服从 × 长高下文 × Agent Swarms。
「现时的 Scaling 仍是不再是单纯的资源堆砌,而是要在缠绵服从、长程哀悼和自动化合营上同期寻找鸿沟效应。」
一家公司,同期在优化器、残差联接、防备力架构、跨模态持重这些底层战场上全线推动,这种嘱咐在行业里相配特立独行。
这亦然为什么 Jerry Tworek 会说出「深度学习 2.0」这样的判断。天然不是说 Attention Residuals 这篇论文就能颠覆一切,更多是它代表了一种方法论的回想:不再得志于在已有框架上修修补补,去重新注视那些被整个东说念主手脚「已惩处问题」的基础设施。
要是残差联接不错被重新遐想,那么 Adam 优化器呢?层归一化呢?位置编码呢?深度学习的基础范式本人正在发生变化,这扇门一朝推开,背面的故事就不再是线性外推能瞻望的了。
Karpathy 那句「Attention is All You Need 还没被畅通透」的咨嗟,大约亦然这个情理。
当年几年,中国 AI 团队的孝敬更多集聚在工程落地和应用更动上,在底层架构表面方面的原创性冲突相对稀缺。Kimi 这篇论文走的是一条实足不同的路线——一个调理的表面框架,一个优雅的工程完结,加上严谨的大鸿沟实验考据。
天然,Kimi 这篇论文还有留住不少需要惩处的问题。论文的大鸿沟考据是在 48B 总参数(3B 激活参数)的模子上完成的,这个鸿沟放在今天的第一梯队里并不算大。在着实的千亿乃至万亿参数模子上,1.25 倍的等效上风能否稳住,咫尺如故个问号。
同期论文展示的也仅仅预持重阶段的收益,经过请示微调、RLHF 等后持重设施后,AttnRes 的上风是否会被稀释,艰辛数据。
但话说回来,这些局限刚巧亦然遐想力的来源。一个仅需约 100 行代码改革、增多不到 4% 持重支拨的轻量修改,就能在 48B 鸿沟上带来这样的晋升。
当它被应用到更大鸿沟的下一代模子上时,收益的天花板在那儿,谁也说不准。
Attention Residuals 举高了 Token 服从的天花板,Kimi Linear 拓展了长高下文的范围,Agent Swarms 指向智能体合营的将来。当这三条技巧线不才一代模子中汇合,呈现出的可能即是新的范式转机。
在 AI 这座通天塔的工程上,整个东说念主都在争着往上保驾护航,而 Kimi 折腰往路基重重地凿了一锹,恰好撬动了深度学习的地基。
作家:莫崇宇开云体育,李超凡
声明:新浪网独家稿件,未经授权谢却转载。 --> 幸运彩app官方网站下载 备案号:
备案号: